Archives à la demande sur S3

Publié le rustawss3lambda
Introduction #
L’année dernière, j’ai fêté mon PACS avec une centaine de personnes. Pour l’occasion, j’avais créé une application web pour gérer les invitations, les choix de menu de chacun, la transmission d’informations et… les photos. Ma femme et moi voulions que les photos puissent être centralisées à un seul endroit, que chacun des invités puisse les téléverser, les visionner et les télécharger. Et c’est là que vous commencez peut-être à voir le rapport avec le titre de l’article.
Pour créer tout ça, je me suis bien entendu tourné vers une solution Serverless sur AWS. Et concernant le stockage des photos, j’ai évidemment choisi Amazon S3 avec Intelligent-Tiering actif, soit la meilleure solution possible quand l’objectif est que ce soit fiable, le moins cher possible et sans rien à gérer une fois en place.
Et donc je voulais que mes invités puissent télécharger les photos. Bien entendu, puisqu’elles sont dans S3, il aurait été relativement facile de faire en sorte que l’application génère une PreSigned URL[1] pour télécharger une photo[2], mais comme j’anticipais d’avoir des centaines voire des milliers de photos, les télécharger une par une de cette manière semblait peu pratique. J’ai donc commencé à réfléchir à une solution pour qu’un invité puisse faire sa sélection de photos (y compris “toutes” le cas échéant) et demander la création d’une archive à télécharger.
Hypothèses de travail #
Au moment de développer la solution, je n’avais pas vraiment d’idée sur la volumétrie cible. Par contre, j’étais complètement sûr de ne pas vouloir que ma solution tire la langue une fois en prod ! Une partie des invités étaient aussi des collègues, donc mon honneur d’Architecte Cloud était en jeu ! 😤
Pas question que ça rame ou que ça plante en conditions réelles, j’ai donc préféré voir large sur les hypothèses de travail :
- une photo c’est ~5 Mo ;
- il y aura 3 000 photos ;
- le système doit être capable de répondre à un “Télécharger tout” ;
- l’archive correspondante doit être crachée en 5 minutes max.
Je dois donc créer une solution capable de télécharger 3000 objets et 15 Go depuis S3, puis d’uploader une archive de 15 Go[3] en moins de 5 minutes.
Lambda #
Il y a évidemment des tas de manières de faire ça, mais j’avais une contrainte (peut-être un peu auto-imposée, je l’admets 😅) : je suis dans un contexte serverless ! Il est donc hors de question de ramener une instance EC2 pour faire le job. Un conteneur ECS sur Fargate aurait pu être envisagé, mais je préfère toujours travailler avec Lambda. Et puis je n’allais quand même pas claquer un cluster ECS juste pour ça 🙄.
Donc la solution doit tenir sur Lambda, ce qui impose certaines contraintes :
- 15 minutes maximum ;
- 10 Go de RAM maximum ;
- 10 Go de stockage local maximum (ce que vous avez à disposition dans
/tmp).
Au niveau du temps, pas de problème avec la limite des 15 minutes : je veux de toute façon que ça aille plus vite que ça.
Au niveau de l’espace en revanche, c’est beaucoup plus intéressant.
La contrainte d’espace #
15 Go à rapatrier, 15 Go à renvoyer… et maximum 10 Go au milieu. Cela exclut complètement une solution séquentielle “naïve” de type télécharger tout, puis compresser, puis uploader le résultat. Dans le pire des cas, il faudrait disposer de 30 Go de stockage (les photos + l’archive), et dans le meilleur des cas 15 Go si vous créez l’archive en supprimant les photos au fur et à mesure. Donc ça ne passe pas : il faut streamer, c’est-à-dire uploader l’archive au fur et à mesure qu’on télécharge les photos.
On pourrait m’objecter que je pourrais me passer de Lambda, ou même que je pourrais utiliser un espace de stockage EFS pour m’affranchir de cette contrainte. C’est vrai, mais en réalité la solution naïve est également incompatible avec l’ambition des 5 minutes. Dans un problème de ce genre, on peut facilement se convaincre qu’ultimement la limite viendra du débit réseau : on doit faire transiter beaucoup de données en aller-retour vers S3. Si on imagine qu’on a une bande passante de 600 Mb/s symétrique à disposition[4], alors la solution “naïve” ne peut pas faire mieux que (15 Go * 8) Gb / 0.6 Gbps = 200 secondes pour télécharger, puis de nouveau 200 secondes pour uploader, soit 400 secondes en tout : plus de 5 minutes ! Et notez que ça ne compte même pas le temps de création de l’archive…
Si on stream en revanche, on utilise la bande passante descendante et la bande passante montante en même temps ! Et la création de l’archive se fait au fil de l’eau. Du coup, on peut espérer faire un peu plus de 200 secondes en tout : c’est beaucoup mieux, et c’est moins de 5 minutes !
Voyez plutôt :
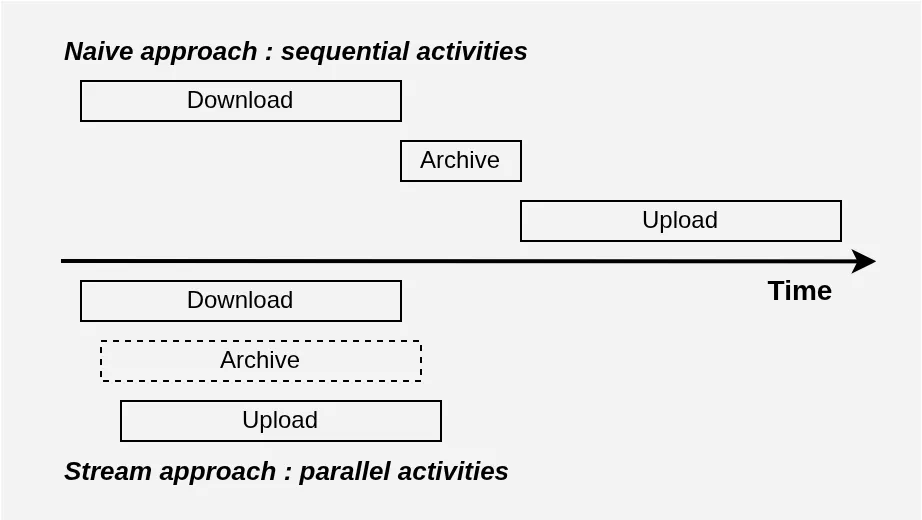
Mais est-il possible de streamer dans notre cas ?
Streamer la création d’une archive ZIP #
Écrire un programme qui télécharge et uploade en même temps, c’est plutôt facile. Mais qu’en est-il de la création de l’archive ZIP ? Peut-elle être streamée ?
En principe, un algorithme de compression a besoin de voir l’ensemble des données à compresser pour fonctionner efficacement[5]. Or, dans notre cas c’est impossible : on veut justement éviter de tout télécharger avant de commencer la création de l’archive. Par ailleurs, on doit aussi éviter les retours en arrière lors de l’écriture : une fois qu’on a envoyé un morceau de notre archive à S3, il devient difficile de le modifier. Ce dernier point est particulièrement problématique avec le format standard de fichier ZIP[6].
En pratique, il vaut mieux abandonner la compression, qui est de toute façon inutile avec des formats d’images déjà compressés. Le format ZIP permet justement un mode “archive-only” sans algorithme de compression. Mieux encore, il propose un mode d’écriture “streaming” qui garantit qu’il n’y a jamais de retour en arrière.
En principe, on peut donc commencer à créer notre archive et envoyer les morceaux au fur et à mesure grâce à la feature multipart upload[7] de S3 :
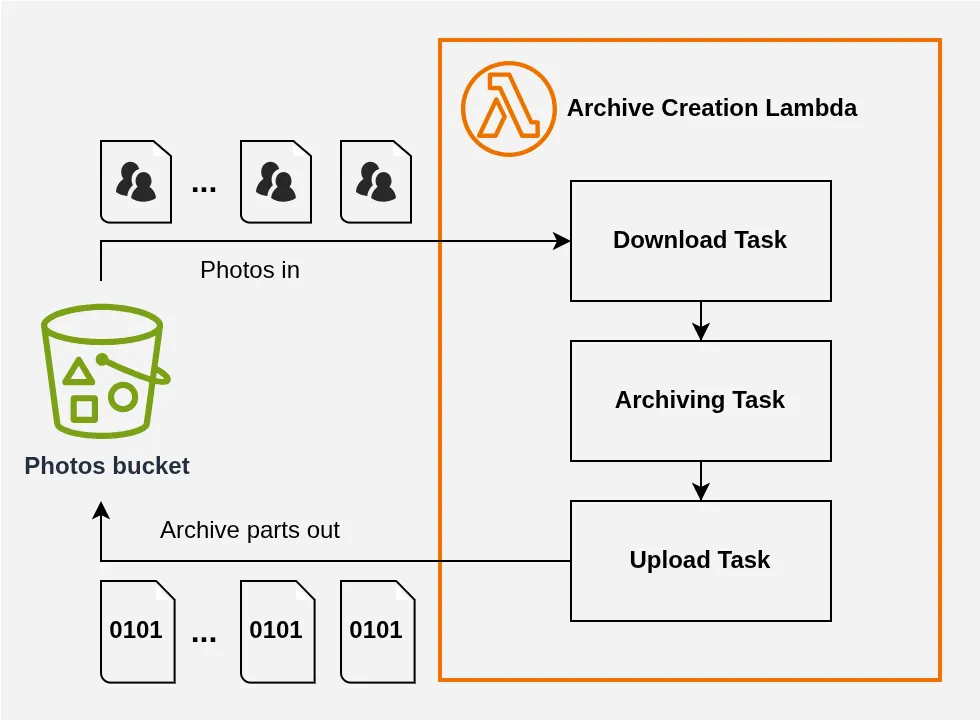
On avance, mais une amélioration s’impose.
Saturer la bande passante #
Le schéma précédent montre une seule tâche de download et une seule d’upload, or nous ne voulons pas télécharger (ou uploader) les fichiers un par un séquentiellement : ce serait un gâchis des ressources !
Déjà, l’ouverture et la fermeture des connexions TCP et TLS sous-jacentes aux downloads (et uploads) sont certes négligeables en termes de volume, mais elles nécessitent des négociations qui génèrent des allers-retours avec le service[8] et prennent du temps. Ce sont donc des phases pendant lesquelles la bande passante n’est pas utilisée, ce qui nous éloigne du meilleur temps théorique (par exemple, ~200 secondes avec 600 Mbps, voir Figure 1).
Ensuite, le protocole TCP est remarquable dans sa capacité à s’adapter aux variations de la bande passante disponible[9], mais le revers de la médaille est que ça lui donne une certaine inertie : la montée en débit d’une nouvelle connexion est relativement lente. Pour saturer la bande passante, il est donc avantageux d’avoir toujours une majorité de connexions qui sont à leur plein débit potentiel.
Si nous faisions des téléchargements séquentiels, ces deux phénomènes rendraient l’utilisation de la bande passante sous-optimale :
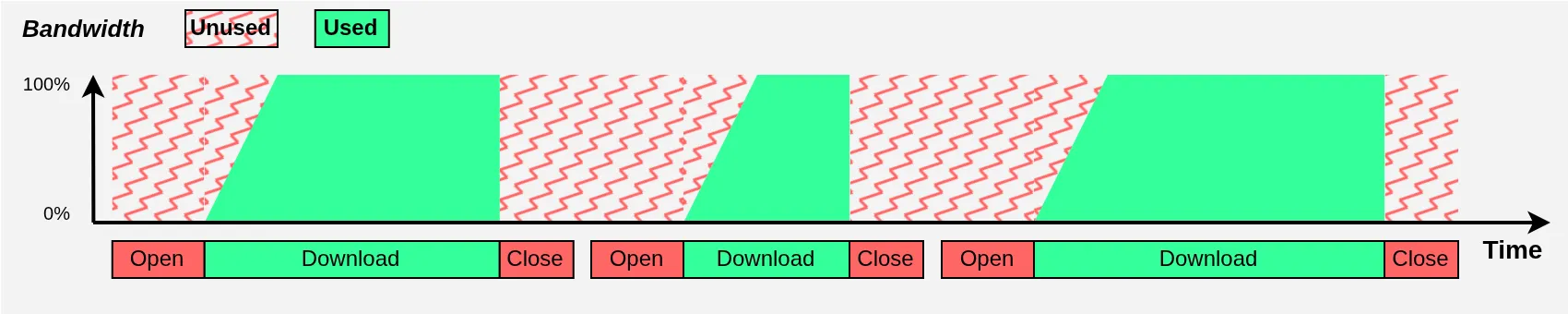
J’accentue évidemment les deux phénomènes pour l’illustration, et on voit bien qu’il y a une grosse perte d’efficacité. Mais regardez ce qui se passe en utilisant plusieurs threads de téléchargement en parallèle :
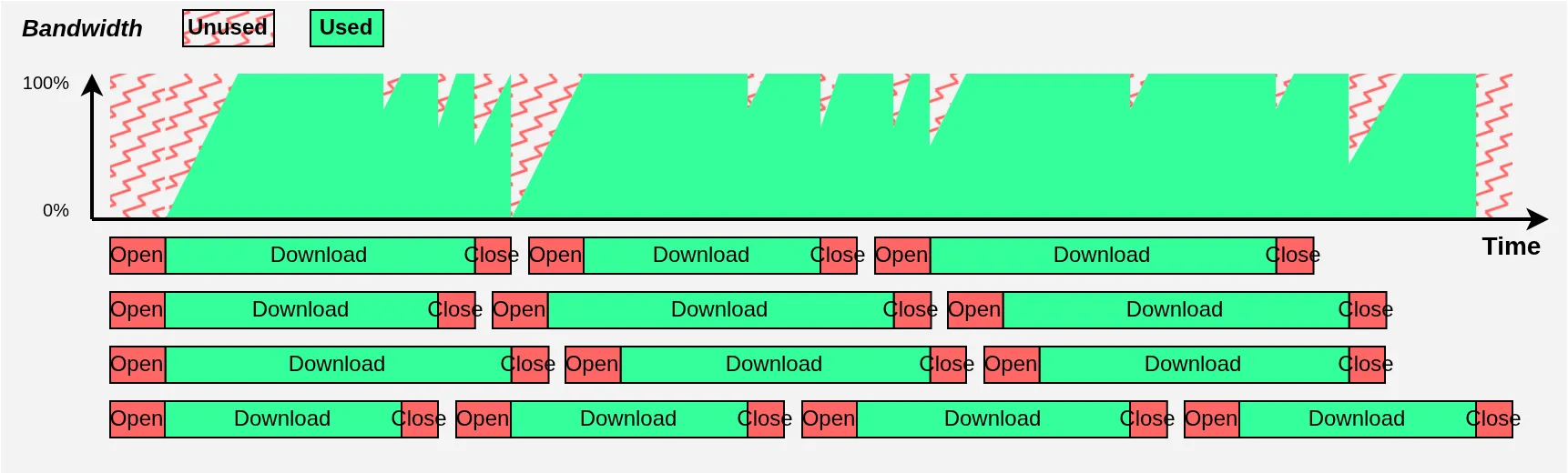
C’est beaucoup mieux !
Déjà, comme la bande passante est partagée entre plusieurs connexions, le temps de téléchargement de chaque connexion s’allonge, ce qui réduit l’importance relative des ouvertures et fermetures. Mais surtout, lorsqu’un téléchargement se termine on ne perd plus soudainement 100% d’occupation de la bande passante comme sur le schéma précédent : on perd seulement la part qu’occupait ce téléchargement. Les téléchargements toujours en cours vont immédiatement réagir (merci TCP) et se partager la bande passante nouvellement libérée pour rapidement revenir à 100%.
Au final, même avec seulement 4 threads pour l’illustration, on occupe beaucoup mieux notre bande passante. En pratique, on peut utiliser une vingtaine de threads pour rester en permanence proche des 100% d’occupation[10]. Notez également que je me suis concentré sur le download dans les schémas, mais la même logique est applicable aux uploads, qui seront donc également multi-thread.
Notre schéma de principe mis à jour devient donc :
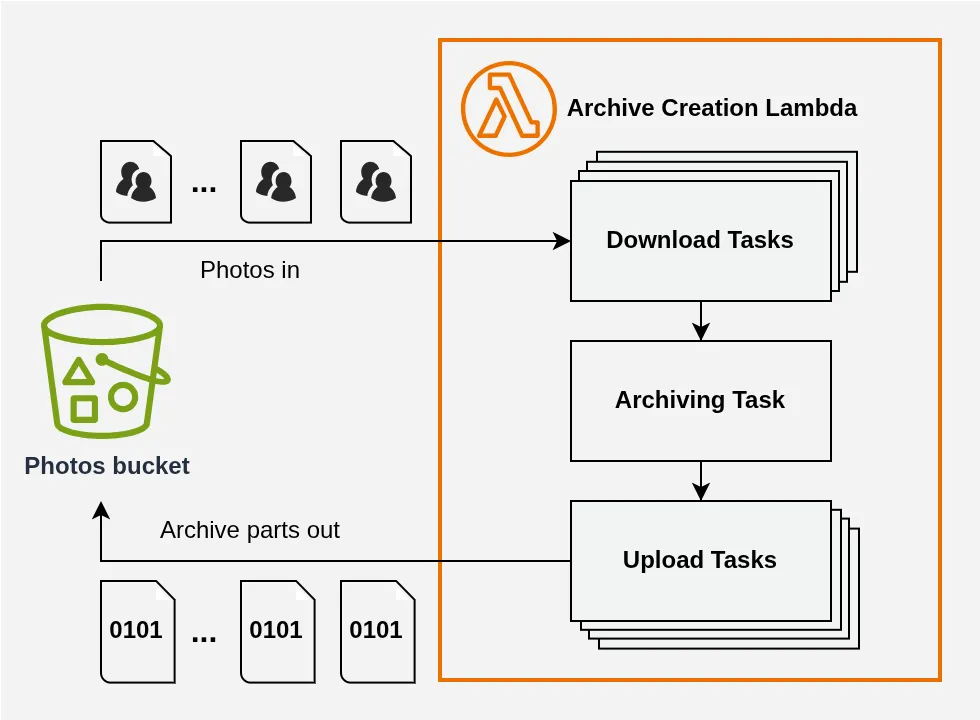
Notez que l’archivage reste en single-thread : il n’y a rien à gagner à paralléliser cette tâche qui sera de toute façon plafonnée par la vitesse du réseau, et ce serait de toute façon impossible à orchestrer.
Et avec ça, nous arrivons à la véritable difficulté : la gestion de la mémoire.
Gérer la mémoire correctement #
Si vous êtes habitués à écrire vos Lambda avec des langages comme NodeJS, Python, Java ou Go, vous êtes sans doute habitués à traiter l’utilisation mémoire de votre programme comme une contrainte imposée à partir de laquelle vous choisissez la configuration de vos fonctions Lambda. C’est normal. Après tout, une des promesses principales des langages objet est de gérer la mémoire automatiquement, et de fait le contrôle du programmeur sur cette gestion est limité.
Cependant, dans un cas d’usage comme celui qui nous intéresse, c’est problématique.
Au minimum, 30 Go vont être écrits dans la mémoire de notre Lambda : les 15 Go de photos qui seront téléchargés et les 15 Go d’archive qui seront calculés[11]. Pour que notre création d’archive se passe bien, il est donc crucial de libérer la mémoire au fur et à mesure, même si notre Lambda était configurée avec le maximum de 10 Go de RAM.
Autre point connexe : la quantité de mémoire minimum nécessaire aux opérations. Si on reprend les valeurs déjà évoquées de 5 Mo par photo en moyenne et de 20 téléchargements simultanés, on conclut qu’on doit avoir au minimum 20 x 5 Mo = 100 Mo de mémoire dédiée aux photos avant archivage. Par symétrie, on peut également tabler sur 100 Mo pour les parties de l’archive en cours d’upload. On conclut alors qu’on doit disposer de 200 Mo de mémoire minimum, dans le meilleur des cas : si on suppose qu’il n’y a aucune duplication inutile de la donnée au cours du processus.
Or, les langages objet utilisant un garbage-collector[12] tels que ceux que j’ai cités plus haut sont très mal équipés pour répondre à ce genre de contraintes :
- le GC doit libérer de la mémoire très souvent, mettant en pause l’exécution du programme et impactant les performances globales ;
- initialement, le GC pourrait essayer d’occuper tout l’espace disponible (coucou Java), ce qui pourrait causer des réallocations de plus en plus coûteuses, là encore impactant gravement les performances[13] ;
- le programmeur a une maîtrise limitée sur la copie des données en mémoire, la quantité de mémoire nécessaire aux opérations peut donc largement dépasser les 200 Mo calculés précédemment, de même que la quantité totale de données écrites pourrait largement dépasser les 30 Go, amplifiant ainsi les impacts précédents ;
- on pourra peut-être compenser en augmentant la mémoire de notre Lambda, sans pour autant améliorer le temps total d’exécution : une augmentation des coûts sans réelle contrepartie[14] ;
- la nature autonome du GC et son impact sur les performances induisent potentiellement une grande incertitude sur le temps nécessaire à la création d’une archive, ce qui complexifie la validation de l’objectif moins de 5 minutes.
NB : Notez que ces points sont surtout valables pour Java, Python et JS. Go est équipé d’un GC, mais il est justement optimisé contre ces problèmes, il serait donc intéressant de voir s’il peut répondre à notre use-case.
Il y a quelques mois, j’ai eu l’occasion de parler avec un client qui avait eu un use-case très similaire à celui que nous étudions. Il me rapportait qu’ils avaient essayé d’écrire une Lambda en NodeJS, et que peu importe la mémoire qu’ils configuraient, ils observaient toujours une dégradation progressive des performances au cours de la création de l’archive qui se soldait systématiquement par l’échec (lambda timeout), pour une volumétrie très inférieure à ce que nous étudions dans cet article. C’était une discussion fortuite à la pause-café et je n’ai pas eu l’occasion de voir leur code : je ne peux donc rien affirmer sur les causes de l’échec. Mais je ne suis pas étonné et je soupçonne que ça a à voir, au moins en partie, avec les problèmes posés par un garbage collector.
Voyons ce qui pourrait marcher.
Une solution théorique #
Le système dont on a besoin doit cocher quelques cases :
- éviter au maximum de dupliquer/copier inutilement les données en mémoire afin de s’approcher du minimum théorique nécessaire évoqué précédemment (200 Mo) ;
- réguler automatiquement le download et l’upload pour maintenir l’équilibre entre les photos qui arrivent et les morceaux d’archive qui repartent, même si (par exemple) la bande passante de download est supérieure à la bande passante d’upload ;
- supporter la création en stream de notre archive.
Ce dernier point sur le streaming n’est pas aisé quand on parle d’une création d’archive, il demande de réconcilier des injonctions contradictoires :
- la tâche d’archivage doit disposer d’un buffer en apparence continu et illimité pour écrire l’archive ;
- alors que la taille de cette archive, et donc de ce buffer, va de très loin dépasser la RAM disponible dans tous les cas ;
- et que, dans le même temps, les tâches d’upload ont besoin de morceaux bien délimités et numérotés pour le multipart upload vers S3.
Cela demande la création d’une structure de données sur mesure pour notre problème. Pour ma part, le “continu et illimité” m’a immédiatement fait pencher vers une variante de Ring Buffer[15] et, après quelques essais et raffinages, voici ce que j’ai conçu :
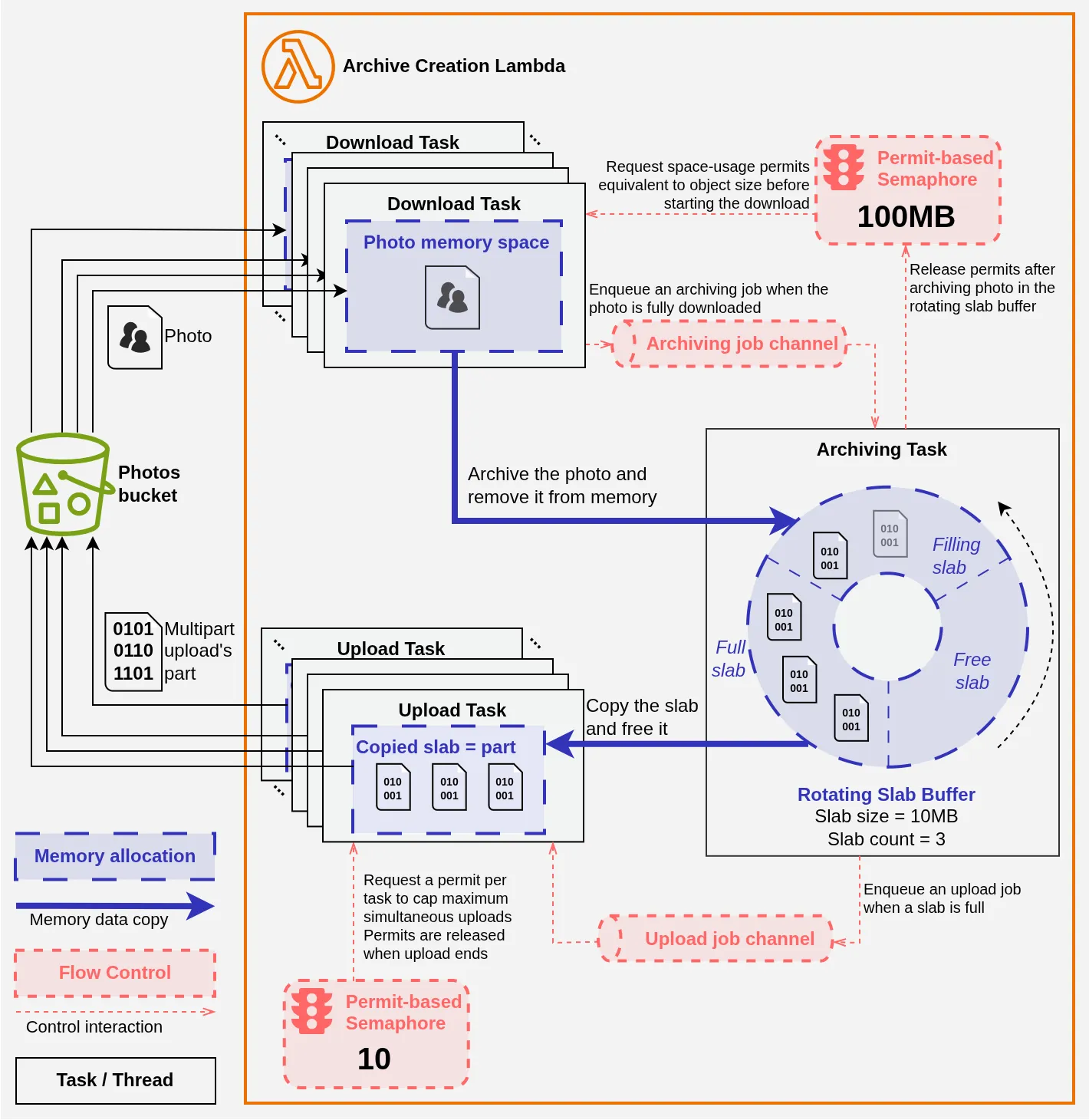
Le schéma est dense, mais vous allez voir qu’en principe il n’est pas si compliqué. Il représente nos différentes tâches (download, compression et upload) et leurs interactions :
- avec la mémoire ;
- avec les systèmes de contrôle permettant de réguler le flux de données.
Download #
Les tâches de download écrivent chaque image en mémoire dans un buffer individuel. Pour limiter l’espace mémoire globalement occupé par les photos avant archivage, chaque tâche de download doit s’attribuer un permis pour chaque octet de l’image à télécharger auprès d’un sémaphore[16] disposant de ~100 millions de permis (100 Mo donc). Lorsqu’il n’y a pas assez de permis, la tâche attend et ne démarre pas le téléchargement. Les permis ainsi acquis resteront associés à l’espace mémoire occupé par l’image jusqu’à sa libération. Ainsi, on s’assure qu’il ne peut pas y avoir plus de 100 Mo de photos téléchargées ou en cours de téléchargement en mémoire à tout instant.
Lorsqu’une tâche de téléchargement s’achève, elle le signale à la tâche d’archivage via un canal de communication dédié (le Archiving Job channel du schéma). La tâche d’archivage lit la photo et l’archive dans un buffer interne, puis libère la mémoire occupée par la photo et retourne les permis associés au sémaphore, permettant ainsi à d’autres tâches de téléchargement de démarrer.
Archivage et Upload #
La tâche d’archivage utilise une librairie ZIP à laquelle j’expose le Rotating Slab Buffer : c’est la pièce maîtresse du système qui permet de réconcilier les injonctions contradictoires évoquées plus haut.
Le Rotating Slab Buffer utilise le système de traits[17] de Rust pour “faire croire” à chaque tâche qu’elle dispose de la structure de données appropriée :
- le trait Write permet de le présenter à la tâche d’archivage comme une section de mémoire continue et infinie ;
- par ailleurs, il est vu comme un itérateur produisant des buffers ordonnés de taille fixe par les tâches d’upload.
Concrètement en interne, c’est un buffer circulaire pré-découpé en dalles de données (“Slabs” en anglais) qui représentent chacune une future partie du multipart upload vers S3. Lorsque la librairie Zip écrit, on remplit la slab Filling. Lorsque cette slab est remplie, on la marque comme Ready et on continue simplement à écrire dans la slab Free suivante qui devient donc Filling. En parallèle, on signale qu’une slab est Ready aux tâches d’upload via un canal de communication dédié (l’Upload Job channel du schéma).
Une tâche d’upload essaie alors d’acquérir un permis auprès d’un sémaphore. Une fois qu’elle l’a obtenu, elle copie le contenu de la slab et la marque Free, de sorte qu’elle puisse être de nouveau utilisée par la tâche d’archivage. Il ne reste plus qu’à uploader les données vers S3 en tant que partie du multipart upload. Les slabs étant garanties d’être exposées dans l’ordre aux tâches d’upload, incrémenter un simple compteur partagé permet de numéroter correctement le multipart upload.
Et voilà.
Régulation du flux de données et mémoire maximum utilisée #
La beauté du système, c’est qu’il s’équilibre tout seul et évite l’accumulation de données en mémoire de manière complètement passive : nul besoin de synchroniser explicitement les tâches de download et d’upload. En décrivant le fonctionnement de cette régulation passive, on peut également calculer la quantité maximale théorique de mémoire qui sera consommée par le programme.
Considérons ce qui se passe si l’upload est plus lent que le download, c’est-à-dire si on rentre la donnée plus vite qu’on ne l’évacue :
- On se retrouve rapidement avec 10 tâches d’upload en cours, le maximum permis par le sémaphore, chacune ayant une copie de slab faisant 10 Mo : on a donc
10 x 10 Mo = 100 Mode mémoire ; - Aucune nouvelle tâche d’upload n’étant permise, notre Rotating Slab Buffer se retrouve avec uniquement des slabs
Ready, soit3 x 10 Mo = 30 Mode mémoire ; - La tâche d’archivage ne pouvant plus écrire les images, elle ne libère pas la mémoire associée, ni les permis de download qui y sont attribués ;
- on accumule les downloads complétés jusqu’à être proche du maximum permis par le sémaphore : 100 Mo ;
- à ce stade, plus rien ne se passe jusqu’à ce qu’un upload se termine, remettant ainsi tout le système en marche.
En tout, on consomme donc 100 Mo + 30 Mo + 100 Mo = 230 Mo de RAM au maximum[18].
De la théorie à la pratique… #
En presque 30 ans depuis mon premier programme, j’ai utilisé beaucoup de langages :
- VB, mon tout premier ;
- C, celui qui a forgé mes connaissances systèmes ;
- pas mal de ☕ Java à l’école ;
- beaucoup de 🐍 Python dans ma vie professionnelle sur AWS ;
- et une dizaine d’autres plus anecdotiques.
L’expérience que j’ai acquise, c’est que les plans sur la comète de belle mécanique algorithmique bien huilée sur Draw.io comme celle que je viens de présenter, c’est super sur le papier, mais l’implémentation c’est une autre histoire.
Déjà dans la vraie vie, la première version du schéma est beaucoup plus proche de la Figure 5 que de la Figure 6 🤣 : le code, ça se travaille, ça se raffine… et quand il est écrit en Python ou JS, ce processus de raffinage est extrêmement douloureux et frustrant. Ensuite, même une fois qu’on a le bon schéma, on se heurte à tous les problèmes que j’ai évoqués avec le garbage collector et d’autres, qui font que le comportement du programme est rarement celui qu’on imaginait.
C’est pour ça que je pense que la seule option raisonnable pour ce cas d’usage sur Lambda, c’est Rust[19] 🦀 ! Et si vous n’êtes pas d’accord… eh bah prouvez-moi que j’ai tort ! 😁
🦀 Rust. #
Dans la longue liste des avantages de Rust, trois en particulier en font le langage de choix pour ce cas d’usage :
- il permet un contrôle précis de l’utilisation de la mémoire ;
- il est méga rapide à l’exécution, ça ne peut qu’aider pour notre limite de 5 minutes ;
- et contrairement à C/C++, il offre ça tout en manipulant des concepts métier, pas des void pointer[20] 😅.
Lorsqu’on parle de Rust, la vitesse d’exécution est souvent mise en avant. C’est vrai que c’est un plus indéniable et compréhensible par tous les publics, mais franchement ce n’est pas là qu’est le principal apport à mon sens.
Un des trucs les plus géniaux dans mon expérience avec Rust, c’est que depuis plus de 3 ans, j’ai des programmes qui se comportent comme je les ai imaginés, du premier coup et avec très peu de surprise. Ensuite, lorsque la phase de raffinage commence, elle se passe bien : le langage est tellement bien structuré qu’il me suffit de changer le type que je souhaite améliorer, puis de me laisser guider par les erreurs du compilateur. Quand le compilateur est de nouveau content, mon programme fonctionne mieux qu’avant. C’est juste génial.
C’est pour ça que je n’imagine plus choisir un autre langage pour mes projets, sur AWS ou ailleurs.
Et effectivement, le soir du PACS, ça a tenu ! 😆
Résultat #
Avec un bucket de 3000 objets d’environ 5 Mo chacun (remplis aléatoirement, c’est plus facile que de trouver 3000 images différentes 😅), ma solution écrite en Rust 🦀 sur une Lambda ARM64 à Paris (eu-west-3) disposant de 512 Mo de RAM crée l’archive en ~215 secondes, soit 3 minutes 35.
Il y aurait sans doute quelques améliorations possibles pour grappiller quelques secondes de plus, mais notez que nous sommes plutôt proches du meilleur temps théoriquement possible de ~200 secondes, étant donné la bande passante maximum de ~600 Mbps sur Lambda. Je trouve également particulièrement remarquable de pouvoir obtenir un tel résultat avec une Lambda ayant seulement 512 Mo de RAM, ça donne un aspect particulièrement économe et satisfaisant à l’ensemble 😌.
Alors, vous pensez pouvoir faire mieux avec votre langage favori ? J’ai pensé à tout et je veux vous faciliter la vie ! J’ai créé un projet de démo sur GitHub très facile à déployer pour peu que vous ayez un compte AWS et un compte GitHub. Je l’ai organisé de façon à faciliter l’ajout d’autres Lambdas dans d’autres langages, et une Step Function se charge de faire l’évaluation des candidats et de fournir le résultat.
🧑💻 👉 https://github.com/RustyServerless/demo-s3-archiving
N’hésitez pas à vous y essayer et à soumettre une PR avec votre solution, je suis extrêmement curieux de voir ce que d’autres développeurs pourraient accomplir sur un tel use-case 😁.
Go ou Swift sont pour moi les challengers les plus sérieux, j’espère voir les PR arriver 😉.
Contactez-moi #
Si vous rencontrez un cas d’usage similaire à celui-ci et que vous souhaitez en discuter, n’hésitez pas à me contacter.
Je propose également d’autres prestations autour de Rust et AWS, et je suis le mainteneur de plusieurs librairies open-source qui peuvent faciliter l’intégration de Rust dans votre écosystème AWS.
La plupart des API AWS permettent de générer des URL pré-signées. Il s’agit d’une URL qui contient dans ses query-strings les informations relatives à un appel futur, ainsi que la signature pour cet appel, réalisée à l’aide des clés d’API d’un rôle ou d’un utilisateur IAM. Ces URLs peuvent ensuite être distribuées à n’importe qui, qui pourra les utiliser pour un temps et dans des conditions déterminées à la signature. L’usage le plus répandu est de très loin la mise à disposition de téléchargement vers ou depuis des objets dans Amazon S3 (téléverser ou télécharger des photos par exemple 😉). ↩︎
Il aurait été encore plus simple de rendre le bucket S3 public en lecture, mais je ne voulais donner l’accès qu’à mes invités ! Il y avait donc de l’authentification via Amazon Cognito et une API GraphQL (AWS AppSync) en backend. L’API faisait tout un tas de choses, dont distribuer des URLs pré-signées à la demande pour les invités authentifiés. ↩︎
Vous avez peut-être envie de penser que si on fait un ZIP de nos 15 Go de photos il fera moins de 15 Go, mais c’est oublier qu’une image JPEG est déjà compressée : il n’y a donc plus grand-chose à gagner. On verra un peu plus loin qu’utiliser la compression est de toute façon inenvisageable. ↩︎
Sur AWS, la bande passante disponible dépend typiquement de la taille de la machine sous-jacente. Avec Lambda, ce n’est pas documenté, mais à date il semblerait qu’on ait 600 Mbps symétriques à disposition quoi qu’il arrive. ↩︎
Le principe général de fonctionnement de ces algorithmes est de détecter les redondances d’information. Pour simplifier (beaucoup), l’idée de base est que si une certaine séquence de bits apparaît plusieurs fois, on lui attribue dans une table de correspondance un code plus court, puis on écrit ce code à la place de la séquence d’origine. Plus une séquence apparaît souvent, plus on lui associe un code court pour gagner le plus d’espace possible. Mais pour savoir quelles séquences sont les plus fréquentes, il faut a priori connaître l’ensemble des données à compresser. Notez que beaucoup d’algorithmes de compression modernes peuvent fonctionner sur une fenêtre glissante et sont donc streamables, au prix d’une moindre efficacité de compression globale. ↩︎
Il y a normalement besoin d’écrire des données dans le header de chaque entrée, dont certaines nécessitent de connaître le fichier entier, sa taille, sa taille compressée et sa somme de contrôle. Ces données ne sont donc connaissables qu’après avoir écrit le fichier en entier. On peut contourner cette limitation grâce aux extensions ZIP64, voir wikipedia si ça vous fascine. 😉 ↩︎
Permet d’uploader un objet dans S3 morceau par morceau, puis de demander au service de recoller les morceaux à la fin. Voir la doc AWS. ↩︎
On parle de “poignée de main” (Handshakes en anglais), TCP et TLS ont chacun le leur, voir wikipedia TCP et wikipedia TLS. Notez qu’il y a généralement des ré-utilisations de connexion pour éviter d’avoir à faire trop de handshakes, mais dans le cas de téléchargements depuis S3 je ne pense pas que ça soit possible. ↩︎
Il y a plusieurs mécanismes à l’œuvre, mais le principal ici est le contrôle de congestion. ↩︎
En réalité, ça dépend de la bande passante disponible, de la latence et de la taille typique des fichiers à télécharger. L’objectif est de s’assurer qu’il y a toujours une majorité de téléchargements en cours sans pour autant que chaque téléchargement individuel prenne trop de temps. ↩︎
Il est en effet très difficile d’éviter une duplication de la mémoire entre la photo “brute” et la photo “incluse dans l’archive”. Même en l’absence de compression, même en supposant qu’il s’agit de la même série d’octets exactement, il reste qu’on parle de buffers différents entre lesquels ces octets doivent être copiés. Notez aussi que c’est un minimum qui suppose qu’aucune autre duplication inutile n’est opérée, et en pratique on en aura certainement. ↩︎
Le principal composant de gestion de la mémoire d’un langage objet. Voir wikipedia. ↩︎
Si vous n’êtes pas féru de programmation système, vous vous imaginez peut-être que quand votre programme a 1 Go de RAM alloué et passe à 2 Go, le système d’exploitation étend simplement l’espace déjà alloué, mais malheureusement ça ne fonctionne pas comme ça. En réalité, un nouvel espace de 2 Go tout neuf va être alloué, dans lequel le programme copie le contenu de son espace précédent. Il est également possible de garder plusieurs espaces mémoire disjoints bien sûr, mais ça peut poser d’autres problèmes. Au final, ce qui se passe exactement dépend du GC dont on parle. ↩︎
On se souviendra que Lambda est facturé notamment au temps d’exécution en fonction de la mémoire allouée : une Lambda avec 1 Go de RAM s’exécutant 1 minute coûte exactement 4 fois moins cher qu’une Lambda avec 4 Go de RAM pour la même durée. ↩︎
Il s’agit d’un buffer dont on connecte le début et la fin, de sorte qu’on peut écrire en continu dedans “comme si” il était infini. On finit ainsi forcément par écraser des données précédemment écrites et il faut donc synchroniser l’écriture et la lecture pour en tenir compte. Voir Wikipedia pour en savoir plus. ↩︎
Un Sémaphore est une structure de données partagée entre plusieurs tâches/threads pour les coordonner. Voir Wikipedia pour en savoir plus. ↩︎
Les Traits en Rust sont une abstraction permettant de représenter des comportements génériques qu’on peut implémenter sur nos types. Similaires aux Interfaces dans certains langages, comme Java par exemple. ↩︎
En pratique c’est plus. Il y a toutes les petites bricoles à droite à gauche pour la gestion des tâches, sémaphores et autres canaux bien sûr, mais c’est complètement négligeable. Surtout, j’utilise évidemment le SDK AWS de Rust pour interagir avec S3, dont je ne maîtrise pas les mécanismes d’allocation… et malheureusement AWS s’est montré moins frugal que moi dans sa conception ! De fait, mes tests empiriques montrent une consommation mémoire maximale autour de 350 Mo, ce qui reste remarquablement bas pour traiter des dizaines de Go de données. 😉 ↩︎
Ok Seb, je t’accorde que Swift ferait probablement très bien le job ! ↩︎
Rust 🦀 est un langage offrant une syntaxe de très haut niveau d’abstraction et un binaire compilé et optimisé à très bas niveau. Une qualité extrêmement remarquable et, à mon avis, très sous-appréciée. ↩︎