Au-delà du streaming d'archive sur S3

Publié le Mis à jour le rustawss3lambda
Introduction #
Il y a quelques semaines, j’écrivais un article à propos de la création d’archives depuis et vers S3, si vous ne l’avez pas lu : Archives à la demande sur S3.
J’y étudiais donc le use-case de créer à la demande une archive ZIP dans AWS S3 :
- de 3000 objets eux-mêmes déjà dans S3 ;
- faisant 5 Mo chacun en moyenne, donc 15 Go en tout ;
- avec une fonction AWS Lambda ;
- en moins de 5 minutes.
L’objectif était de montrer que c’est plus compliqué qu’il n’y paraît, avec notamment l’impératif de bien contrôler le layout et les allocations de RAM, et que Rust 🦀 est LE langage ultime pour adresser un tel use-case.
Je finissais l’article en renvoyant au repo GitHub de la démo, et en lançant un petit défi : me prouver que j’ai tort en faisant mieux avec un autre langage !
Et à ma grande surprise (et mon grand plaisir), ça a pris 😃 !
Les réponses au défi #
À l’heure où j’écris ces lignes, 3 autres développeurs se sont pris au jeu. Voici les résultats rapportés par la Step Function de benchmark :
| # | Génération | Langage | Auteur | RAM (Mo) | Temps moyen (secondes) | Écart-type / Min / Max (10 runs) | Prix / run |
|---|---|---|---|---|---|---|---|
| 1 | 2 | Rust | JRodon | 512 | 106 | 1 / 105 / 107 | $0.000709 |
| 2 | 2 | Rust | Figment Engine (Fitz) | 640 | 119 | 7 / 113 / 128 | $0.000993 |
| 3 | 1 | Rust | JRodon | 512 | 212 | 1 / 211 / 214 | $0.001416 |
| 4 | 1 | Swift | SebSto | 512 | 235 | 13 / 217 / 250 | $0.001568 |
| 5 | 1 | C | SebSto | 640 | 212 | 2 / 210 / 215 | $0.001767 |
| 6 | 1 | Python (3.13) | SebSto | 1024 | 243 | 16 / 211 / 262 | $0.003235 |
| 7 | 1 | TypeScript (Node 22) | SebSto | 1280 | 230 | 20 / 215 / 272 | $0.003833 |
Mention spéciale à Sebastien Stormacq qui a soumis pas moins de 4 PR à lui seul. Un énorme merci Seb 🙏. Sa soumission Swift est la plus avancée. Il a écrit un article à ce propos : Can Swift Match Rust on a Lambda Micro-Benchmark? Almost.[1].
Alors qu’est-ce qu’on peut dire de ces résultats ?
Génération 1 vs génération 2 #
Il y a l’éléphant dans la pièce : la Gen2 est deux fois plus rapide que la Gen1, pour le même langage ! Alors, qu’est-ce donc que cette histoire de génération ?
En fait, Fitz a cassé le game.
Dans mon précédent article, je soulignais que sur Lambda la limite de bande passante à 600 Mbps (symétrique) faisait qu’il était impossible de faire mieux que 200 secondes, c’est-à-dire le temps qu’il faut pour télécharger (et uploader en parallèle) 15 Go à cette vitesse. J’ai fait ce raisonnement sur la base de l’architecture de streaming que je présentais, qui impose de faire transiter tous les objets par la Lambda.
Mais Fitz a décidé de contourner la limite en ayant une idée super smart 💡 : il tire avantage de l’API UploadPartCopy de S3. J’ai été obligé[2] d’en faire ma propre déclinaison et on va justement en parler dans la suite de l’article.
Trois autres devs ? #
Je vois qu’il y en a qui suivent. Effectivement je n’ai parlé que de Seb et Fitz, et ça fait seulement deux.
Paul Santus a également participé, mais à sa façon, en dehors de mon repo de démo. Il a lui aussi cassé le game, mais différemment. L’approche de Paul et celle de Fitz ont un point commun : tous deux tirent avantage de la possibilité de prédire le layout exact de l’archive ZIP dès le moment où on connaît la liste des objets et la taille de chacun comme on va le voir juste après.
Paul en profite pour ventiler la création de l’archive sur plusieurs Lambda, s’affranchissant ainsi de la limite de 600 Mbps de bande passante ! Imaginez : en utilisant 100 lambdas en parallèle, on a 60 Gbps de bande passante, avec ça on traite nos 15 Go en littéralement 2 secondes, c’est complètement imbattable. Vous pouvez lire son article pour en savoir plus : S3 zipper challenge: a parallel zip assembly that beats the single Lambda approach.
Si je reconnais la puissance de l’approche, l’utilisation d’une Step Function au lieu d’une Lambda la place un peu hors-concours. Je n’exclus pas de m’y essayer à un moment (rendez-vous compte, il a fait ses lambdas en Go 😒), mais pour le moment parlons de la Gen2.
Principes de la génération 2 #
Fitz est le premier à avoir implémenté l’idée, donc si vous voulez vous abreuver “à la source”, il a joint un article à sa PR : Rust contender — figment-engine[3].
Les deux observations centrales de son design sont qu’on peut prédire le layout du ZIP et qu’on peut utiliser UploadPartCopy au lieu de UploadPart sous certaines conditions.
Prédire le layout du Zip #
Le layout d’une archive ZIP est assez simple. Un header suivi d’un payload (le fichier, compressé ou pas), et on recommence. L’archive se termine par un Central Directory qui reprend grosso modo les headers de chaque fichier avec l’offset où les trouver.
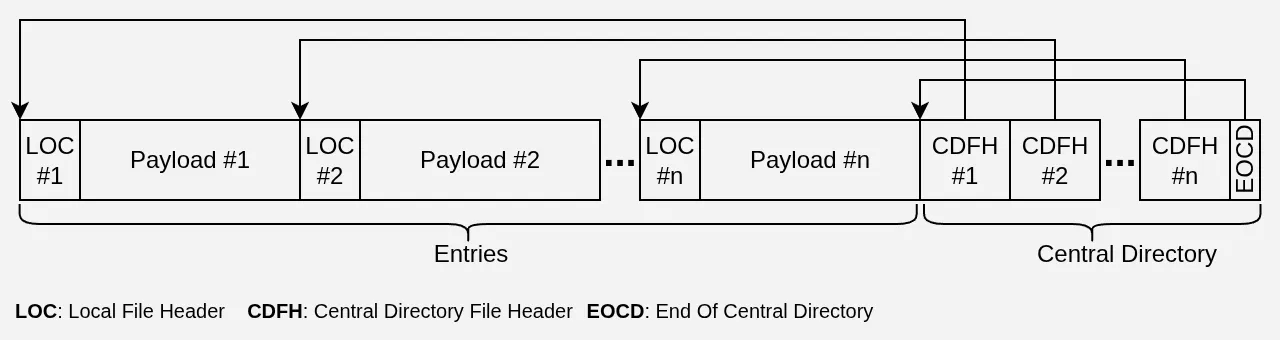
Les Local File Headers (LOC) et les Central Directory File Headers (CDFH) contiennent le nom de chaque entrée, ils ont donc une taille variable mais prévisible. Dès lors qu’on connaît le nom de chaque fichier et la taille de chaque payload, on peut aisément se convaincre qu’il est tout à fait possible de prédire à l’octet près où sera placé chaque LOC, chaque payload et chaque CDFH.
Pour notre use-case, la première étape est de toute façon de faire un ListObjectV2 sur le bucket S3, ce qui nous donne la liste des objets, leur nom et leur taille. Comme on ne compresse pas, le payload est tout simplement le contenu du fichier et fait donc la même taille. Les planètes sont alignées pour savoir exactement comment sera organisé notre ZIP avant même de télécharger quoi que ce soit, mais où est-ce que ça nous mène ?
UploadPartCopy #
La clé d’un gain éventuel, c’est l’existence de l’API UploadPartCopy sur S3, qui permet de lui dire d’utiliser tout ou partie d’un objet existant comme part d’un multipart upload.
Un multipart upload S3 se déroule en 3 grandes phases conceptuellement simples :
CreateMultipartUpload: on dit à S3 qu’on veut envoyer un objet en morceaux, il nous fournit unUploadId;-
UploadPart: on donne à S3 l’UploadId, unPartNumberet on upload de la donnée ;UploadPartCopy: on donne à S3 l’UploadId, unPartNumberet laCopySource, c’est-à-dire le bucket et la clé de l’objet S3 à utiliser comme part, on n’a pas de données à uploader nous-mêmes ;
CompleteMultipartUpload: on signale à S3 qu’on a fini, il utilise lesPartNumberpour coller les morceaux dans l’ordre et hop, on a un nouvel objet dans notre bucket.
À ce stade, une idée géniale nous vient. Il faut bien comprendre que sur une archive de 3000 fichiers / 15 Go, la totalité des headers représente à peine 1 Mo… Donc si on faisait ça :
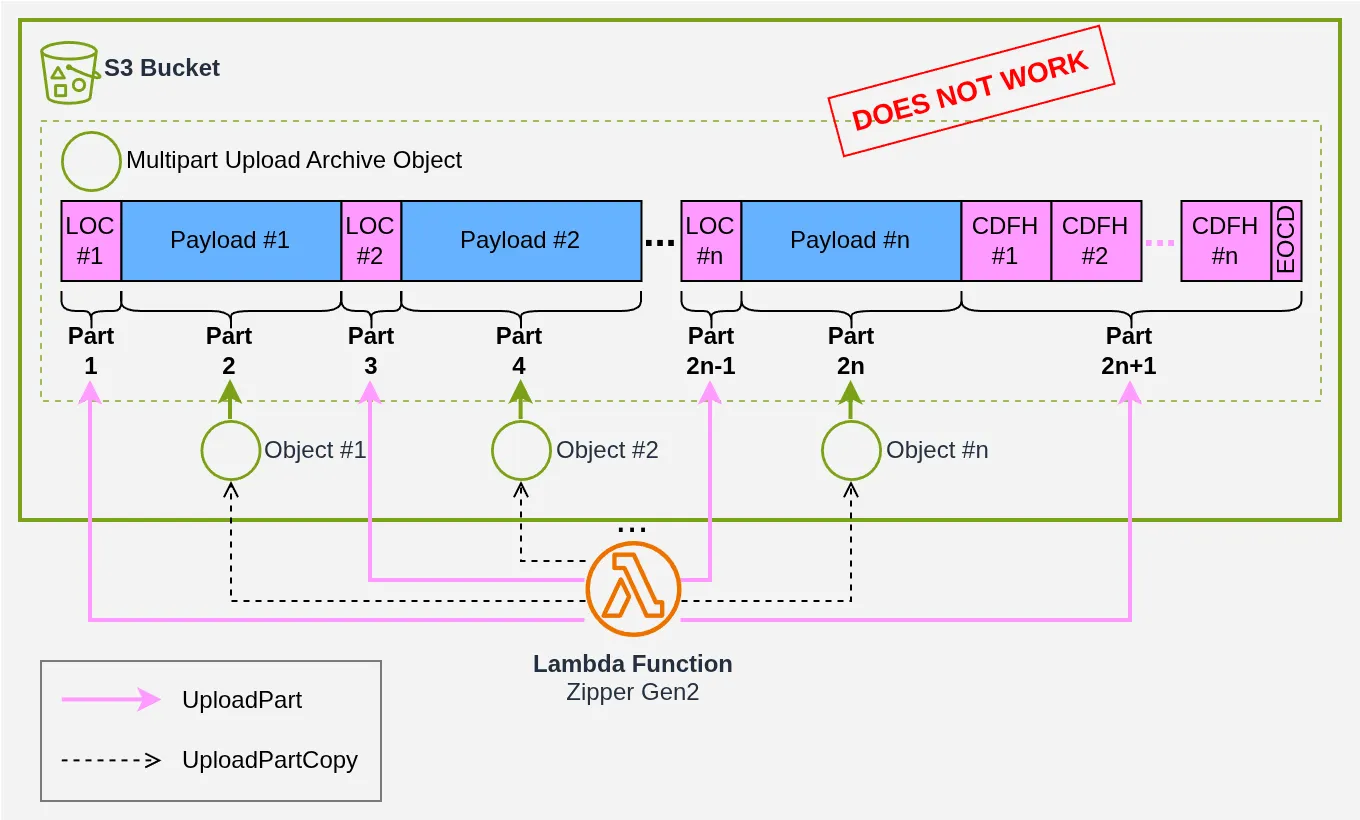
On n’aurait alors qu’à uploader les headers et laisser S3 faire le lien avec les gros morceaux qu’il a déjà. Ça serait génial, non ?
Sauf que malheureusement, S3 impose qu’aucune part ne peut faire moins de 5 Mo (sauf la dernière), donc on ne peut pas mettre en pratique une stratégie aussi naïve :
- un LOC est bien trop petit (~100 octets) pour faire une part à lui seul ;
- les objets de moins de 5 Mo ne peuvent pas être utilisés avec
UploadPartCopy.
Et c’est là que Fitz a été super malin !
On peut séparer les “gros” fichiers (de plus de 5 Mo) et les “petits” fichiers (de moins de 5 Mo), puis on alterne : un UploadPart avec des “petits” fichiers et des LOC, un UploadPartCopy pour un “gros” fichier, et on recommence.
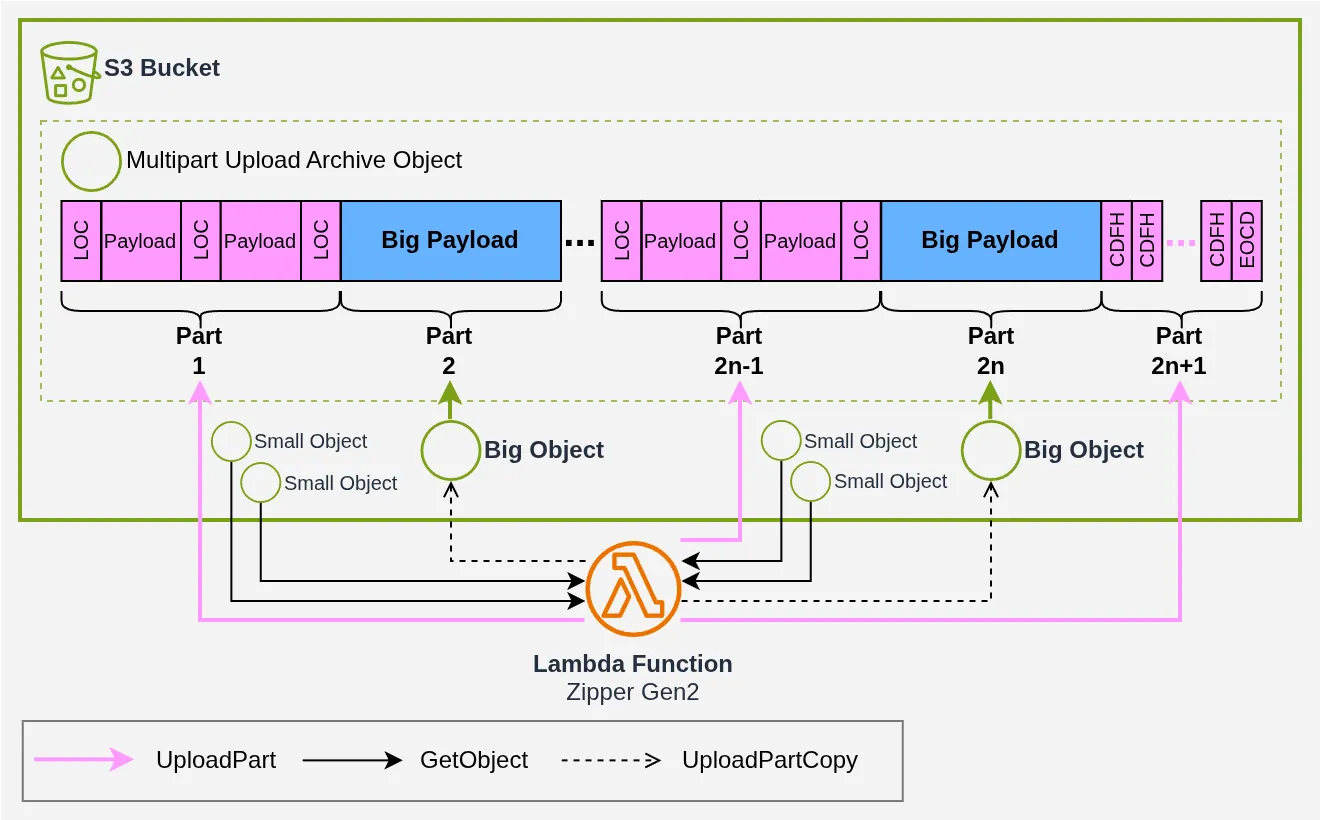
On en revient à télécharger les plus petits objets pour les uploader ensuite, mais au moins on évite de télécharger les plus gros !
Notez sur le schéma que l’alternance entre UploadPart et UploadPartCopy est obligatoire : pour chaque UploadPartCopy d’un “gros” fichier, il faut forcément un UploadPart juste avant pour écrire son LOC, de sorte à obtenir une archive valide à la fin.
C’est brillant en théorie, mais qu’est-ce qu’on peut espérer gagner côté performances ?
Un peu de théorie #
Faire le calcul exact dans le cas général est très vite très abstrait, et je n’ai pas trouvé de moyen de rendre ça lisible pour un article de blog. Donc étudions plutôt le cas particulier de mon petit défi. Il se trouve que les 3000 objets font 5 Mo en moyenne, suivant une distribution normale[4] :
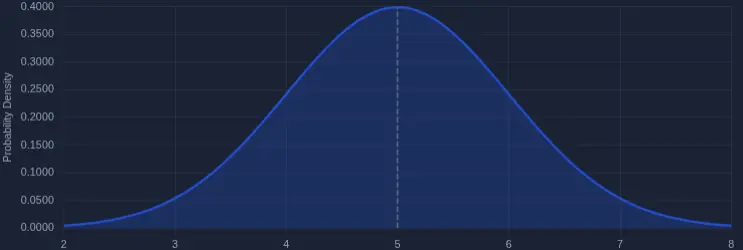
Statistiquement, on peut donc faire des couples : dans chaque couple, on associe un objet de moins de 5 Mo avec un objet de plus de 5 Mo. Chaque couple fait donc 10 Mo : un UploadPart de 5 Mo et un UploadPartCopy de 5 Mo. Le tour est joué, on s’économise exactement 50 % du volume de transfert.
Nan mais Jérémie, tu craques là, on peut pas juste prendre une partie de la taille du gros fichier et la compter dans l’
UploadPart!
Et ben si, c’est possible 😁 ! On peut faire des ranged GetObject pour télécharger partiellement, et des ranged UploadPartCopy pour copier partiellement.
Imaginez par exemple un couple avec un SmallObj de 3 Mo et un BigObj de 7 Mo. Il manque donc 2 Mo pour le UploadPart. On peut alors télécharger les 2 premiers Mo de BigObj pour compléter le UploadPart et faire un UploadPartCopy partiel des 5 Mo restants du BigObj :
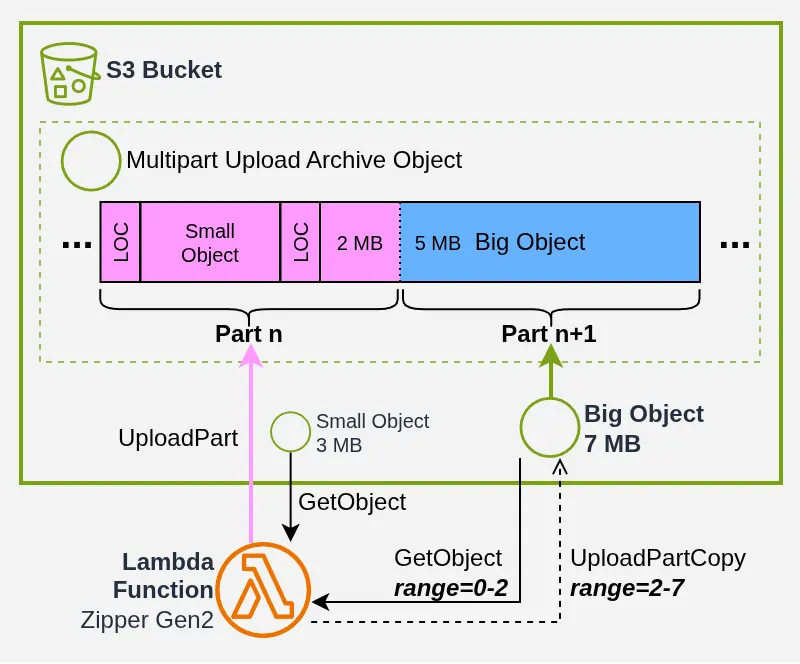
Avec 3000 objets, ça tient à l’échelle : on sera peut-être bloqué pour quelques UploadPartCopy, mais statistiquement on va économiser 50 % du volume de transfert, à plus ou moins epsilon.
NB : je néglige complètement la taille des headers : ils sont trop petits pour que ça change grand-chose au raisonnement, on parle de moins d’1 Mo de headers pour presque 15 Go d’archive.
Le code proposé par Fitz #
Lorsque j’ai vu les performances que Fitz rapportait dans sa PR, j’ai tout de suite compris qu’on pouvait faire mieux. On vient de voir qu’on économise 50 % de volume de transfert en théorie. Comme la bande passante est le facteur limitant de la Gen1, qui la contraint à un minimum de 200 secondes, alors la Gen2 doit pouvoir s’approcher des 100 secondes.
Or, le code proposé par Fitz ne fait “que” ~120 secondes. On est trop loin du compte.
Je n’ai pas analysé son code en détail, mais je l’ai rapidement survolé après avoir écrit le mien (je ne voulais pas être influencé). Les stratégies que nous suivons semblent vraiment très proches[5], les grands esprits se rencontrent 😃 !
Du coup je suppose que c’est l’exécution qui fait la différence[6] ? S’il lit ça, je suis sûr qu’il aura à cœur de comprendre, je lui laisse donc le soin 🙃.
La stratégie #
L’objectif de la stratégie, c’est de faire un maximum de Duo : c’est-à-dire un UploadPart couplé à un UploadPartCopy, évidemment en respectant la contrainte que chaque part fasse plus de 5 Mo.
Quand je dis “un maximum”, il faut comprendre qu’idéalement chaque BigObj (de plus de 5 Mo) doit être inclus dans un Duo en tant qu’UploadPartCopy. Le risque, c’est de ne pas avoir assez de SmallObj (de moins de 5 Mo) pour remplir l’UploadPart. Autre point à considérer : si on ne peut pas mettre tous les BigObj dans un Duo, alors autant mettre les plus gros en premier !
Avec ces observations en tête, j’ai fait un algorithme qui prend en entrée la liste des objets avec leur clé, leur taille et leur nom et qui crache en sortie le layout du Zip. Voici un exemple réel du plan produit pour une archive de 10 objets (j’avais la flemme de faire un diagramme avec 3000 🙄) :
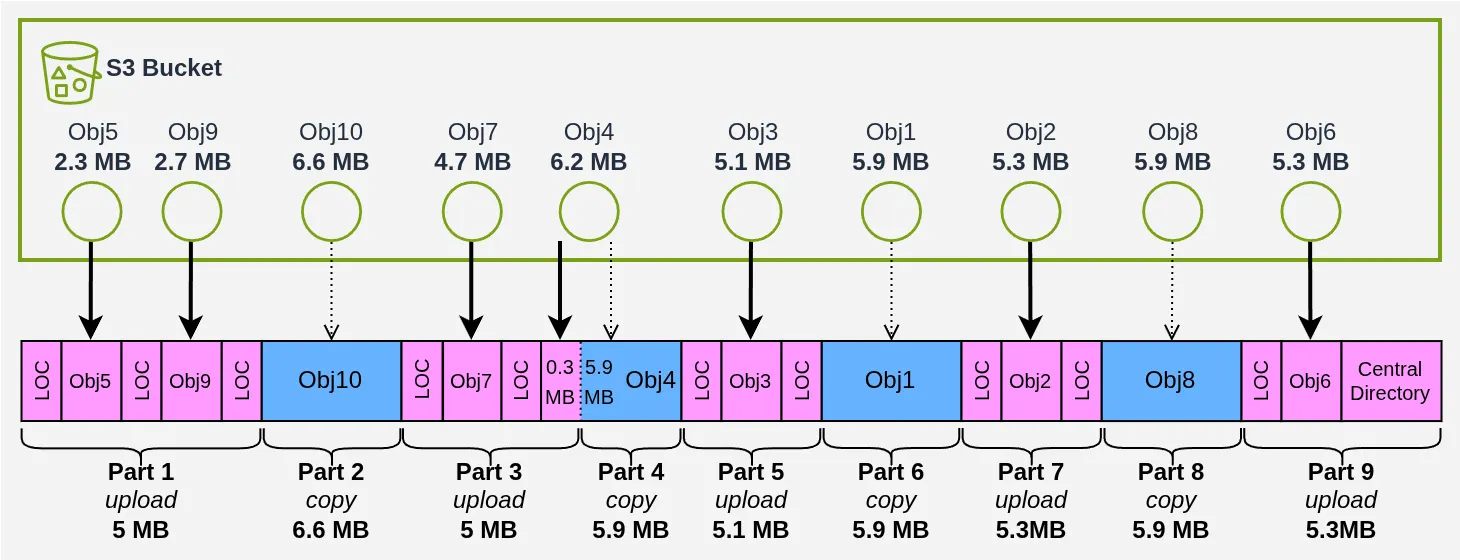
On copie 24,2 Mo et on télécharge/upload 25,8 Mo, presque 50 % d’économie, pas mal non ? Le code est commenté et accessible dans le repo pour ceux que ça intéresse de voir comment on arrive à ce résultat.
Je précise que mon algorithme ne garantit pas d’aboutir systématiquement à la meilleure solution[7], mais il a l’avantage de ne nécessiter qu’un tri par taille (complexité : O(n.log(n)) par rapport au nombre d’objets à archiver) et ensuite quelques parcours de la liste (un nombre fixe de fois, donc complexité : O(n)). J’ai des idées sur comment faire (un peu) mieux, mais il faudrait augmenter la complexité et introduire un peu de O(n2), ce que j’essaie d’éviter en général 😅.
L’exécution #
La Gen2 appelle une autre méthode d’exécution que la Gen1.
Pour la Gen1, je décrivais dans mon précédent article une architecture composée de :
- un pool de Download Tasks qui récupère les objets depuis S3 ;
- une tâche d’archivage qui produit l’archive dans une variante de Ring Buffer que j’ai appelé un Rotating Slab Buffer ;
- un pool de Upload Tasks qui upload les Slabs (des morceaux d’archive) comme des parts du multipart upload vers S3 ;
- quelques sémaphores pour assurer la régulation de tout ça.
Mais si j’avais pensé à ce dispositif, c’est justement parce que je ne savais pas à l’avance à quoi allait ressembler l’archive, et notamment les différentes part du multipart upload n’avaient pas de lien avec les fichiers de l’archive ! Le mécanisme de la Gen1 était là pour s’adapter à cet inconnu, mais la Gen2 change les choses.
En effet, en Gen2 on fait beaucoup d’efforts pour entièrement calculer à l’avance le contenu de l’archive : on connaît la place de chaque objet et on pré-calcule le contenu exact de chaque part du multipart upload. Le problème change donc radicalement à mon sens. Une fois la phase de planification initiale passée, on ne peut même plus parler d’archivage ! Tout ce qu’on fait, c’est aller chercher des octets à droite à gauche pour créer nos parts pour les UploadPart, et envoyer des appels UploadPartCopy en parallèle.
J’ai donc décidé de transformer chaque part du plan en un Part Job. Ils sont traités en parallèle, avec un Permit-based Semaphore qui permet de limiter la quantité de mémoire consommée par les UploadPart, qui nécessitent toujours de télécharger et d’uploader :
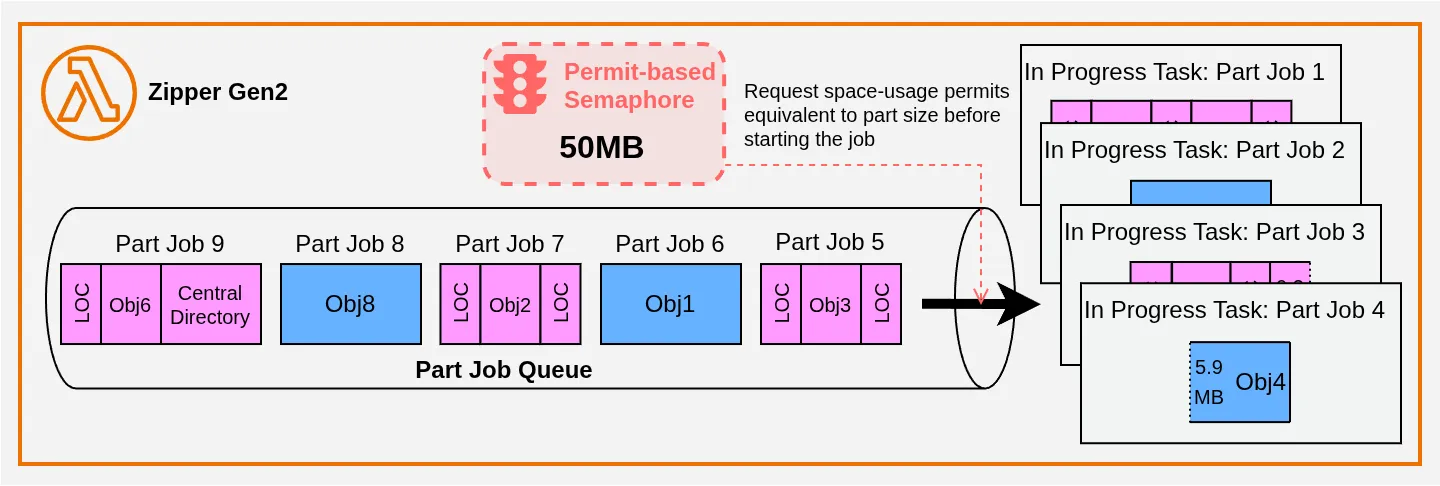
Chaque Part Job exécute un ensemble de sous-tâches qui créent la part dans S3 (pour les UploadPartCopy, c’est juste un appel API S3). Si on prend l’exemple de Part Job 3, les activités ressemblent à ça :
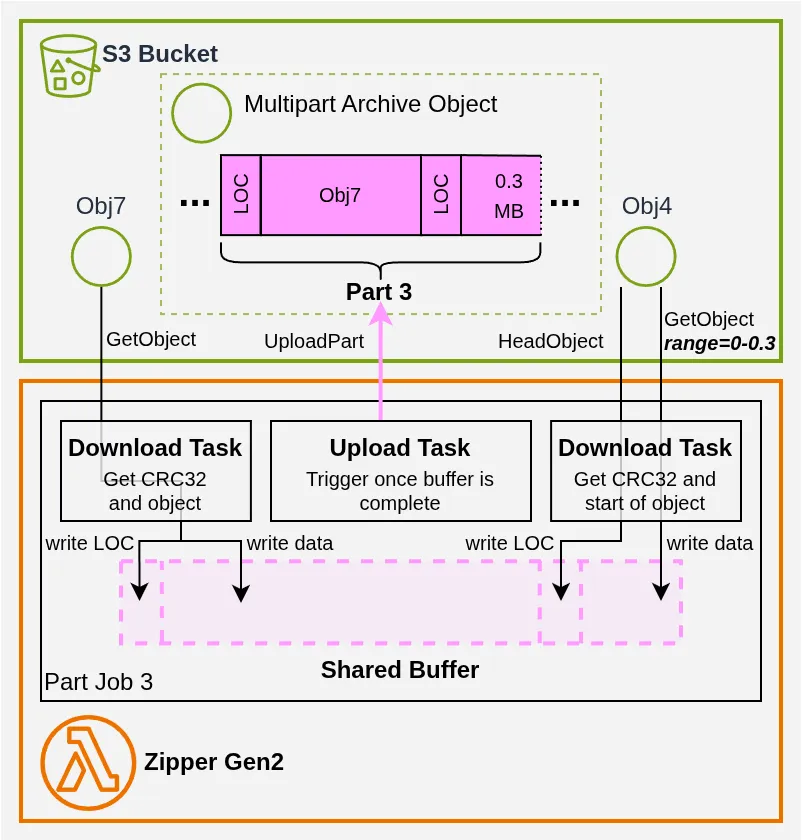
Le Shared Buffer est une petite structure de données que j’ai écrite pour permettre à de multiples tâches (donc potentiellement de multiples threads) d’écrire dans le même buffer, afin d’éviter les copies de données inutiles entre le téléchargement et l’upload.
CRC32 #
Notez également que le LOC (et le CDFH) doivent contenir la checksum CRC32 du fichier. Il se trouve que tous les clients officiels AWS pour S3 (AWS CLI, les SDK, la console) ajoutent systématiquement cette checksum aux objets. On peut donc compter sur sa présence. Un GetObject contient toujours le CRC32 dans sa réponse, sauf s’il est ranged 🤷. Donc pour tous les BigObj, on doit faire un HeadObject afin de récupérer l’information.
L’information du CRC32 récupérée par chaque Part Job doit également être transmise au Part Job final qui se charge d’écrire la dernière part contenant le Central Directory. En Rust 🦀, la librairie tokio, qui permet l’orchestration de milliers (voire millions) de tâches concurrentes et que j’utilise dans tous les projets Rust/Lambda, met à disposition des canaux de type Multiple Producer Single Consumer (MPSC) parfaitement adaptés à ce besoin. Ce n’est pas montré sur les schémas, mais un canal MPSC est créé en même temps que les Part Job : tous obtiennent une copie du sender, sauf le dernier qui obtient le receiver. C’est via ce canal que le CRC32 est transmis. Si ça vous intéresse, voir le code du PartJobsBuilder.
Conclusion #
Au final, ma Gen2 atteint 106 secondes avec peu de variations, exactement moitié moins de temps que ma Gen1 !
Je suis très content que Fitz ait pensé à l’UploadPartCopy. Lors de mon premier article, j’étais tellement fier que les performances de mon code s’approchent de la limite théorique des 200 secondes, que j’en ai oublié de me demander si on pouvait faire différemment. Une leçon à retenir 😉 !
Je dois néanmoins réitérer le challenge avec presque plus de force : la Gen2 est, à mon avis, une architecture encore plus difficile à mettre en musique de manière optimale que la Gen1. Alors, est-ce que quelqu’un va enfin s’y essayer en Go 😏 ?
Contactez-moi #
Si vous rencontrez un cas d’usage similaire à celui-ci et que vous souhaitez en discuter, n’hésitez pas à me contacter.
Je propose également d’autres prestations autour de Rust et AWS, et je suis le mainteneur de plusieurs librairies open-source qui peuvent faciliter l’intégration de Rust dans votre écosystème AWS.
Les chiffres de SebSto sont différents de ceux que je rapporte parce que j’ai optimisé la configuration de chaque Lambda pour les coûts plutôt que pour le temps. De mémoire, la configuration qu’il utilisait de son côté pour sa Lambda Swift était ~750 Mo de RAM. Aussi, d’un moment à l’autre de la journée on n’obtient pas toujours les mêmes résultats mais je n’ai jamais vu le classement changer. ↩︎
Fitz disait dans son post LinkedIn que SebSto l’avait nerd-snipe en parlant de mon petit challenge, c’est donc tout naturel que je me fasse nerd-snipe à mon tour 🤣 ↩︎
Il y a pas mal d’erreurs (de calcul, de raisonnement, sur la scalabilité de la bande passante Lambda, sur un prétendu design qui ferait le taff en 60 secondes…). Néanmoins, les grandes idées sont correctement décrites. ↩︎
Plus précisément, ils suivent une distribution normale centrée sur 5 Mo avec un écart-type de 1 Mo. Pour éviter les extrêmes, le minimum est fixé à 2 Mo et le maximum à 8 Mo. ↩︎
Il fait l’erreur de séparer les BigObj et les SmallObj en deux sources distinctes pour la création de ses duos de
UploadPart/UploadPartCopy, de sorte que lorsqu’il est à court de SmallObj, il arrête de créer des duos et planifie de télécharger tous les BigObj restants. C’est évidemment une erreur : il vaut mieux associer les BigObj restants en duo pour pouvoir en copier la moitié. ↩︎Au minimum, les 3 secondes passées juste à aller chercher des CRC sont gâchées. Mais ça ne peut pas tout expliquer. ↩︎
D’ailleurs, si vous regardez bien l’exemple, on peut faire mieux en inversant Obj7 et Obj6, ce qui permet de copier Obj4 en entier au lieu d’en utiliser une partie pour compléter le
UploadPart(la partie finale fera moins de 5 Mo, mais c’est la dernière donc c’est autorisé). ↩︎